
TL;DR named parameters seems to be possible with only a few additional in-memory copies and a bit of stack pointer manipulation. But what will it mean for debugging?
Okay, let me give this another go. In my previous post about named parameters from 2013 I think I made clear why named parameters are a good idea from the perspective of readability. And readability is the second most important aspect of source code, the first being that it should work of course. However I have not been able to convince mr Goetz to add it to Java. And I really tried a few times, ranging from online to face-to-face discussion. His argumentation every time is that it is way more complex than it seems, but unfortunately he never got around to explaining this.
Once you start with named parameters, they have a tendency to attract more and more functionality, so let’s break down what is possible in increasing complexity:
- Documentation; the fact that for each argument you can put the name of the associated parameter in the calling statement instead of in a comment (see the 2013 post), makes the call more readable.
- Validation; by naming the arguments in the calling statement, the compiler can check if they match the called method’s parameters. It can validate if the intention of the coder matches what is happening.
- Ordering; if the order of the names in the call deviate from the method’s signature, the compiler could reorder the arguments to match.
- Defaults; when named arguments can be matched to their parameter counterparts, any omissions can be filled with defaults.
void rectangle(int height = 0, int width = 0) { // these parameters have defaults
// ...
}
void use() {
rectangle(100, 200); // only from the call it is not obvious what this really defines
rectangle(height=100, width=200); // better readable, and the compiler can validate
rectangle(width=200, height=100); // the compiler could fail on this, or reorder based on the signature
rectangle(width=200); // since all arguments are named, the compiler can infer the value for missing ones
}
I would be perfectly happy with only the documentation option. But if the information is present, not validating it is a missed chance. Both options 1 and 2 are not changing anything to the generated code.
Option 3 and 4 are also logically related; once you start shuffling the order, it is easy to insert defaults for omitted arguments. But these two options do require changes the generated code. Let’s examine what.
Looking at Java, the inner workings on many aspects aren’t that much different from how things worked when I was writing my own compilers and operating systems (including multithreading) in C back in the early 90ies: the compiler at compile time determines how much memory the local variables in a called method need, and how much for the parameters. At runtime the space for the local variables is allocated on a stack, and then the calling method pushes the arguments on top of that. Together with some administrative pointers this is called a stack frame in Java. Simplified it looks something like this:
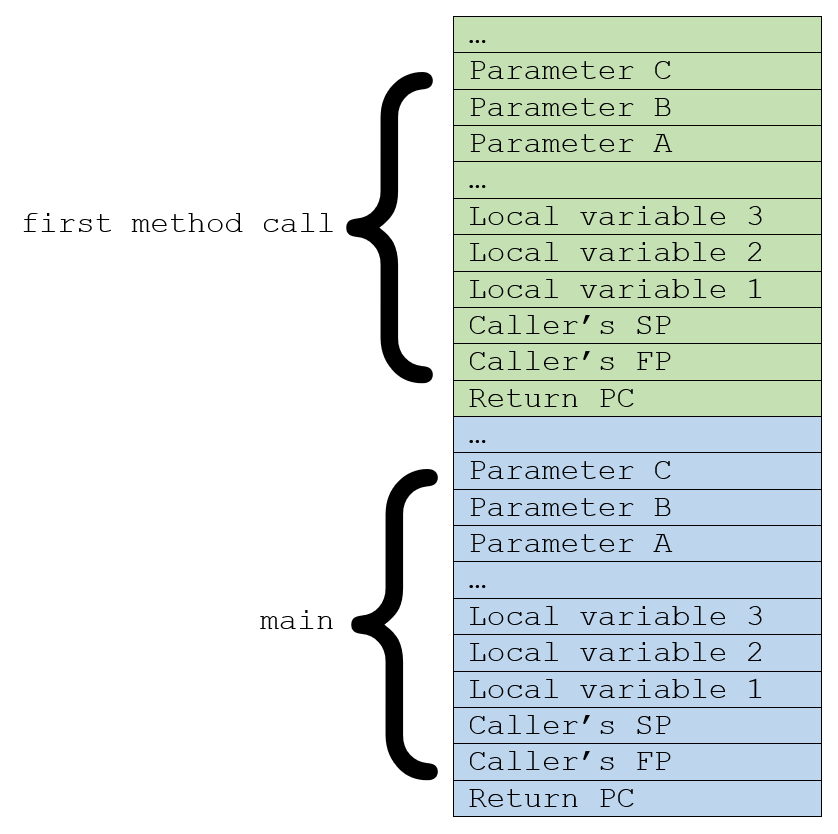
The called method then references its parameters to the arguments on the stack. This is simply done in order; left to right.

Still simplified, calling a method consists of these steps:
- Allocate space on the stack for the local variables.
- Evaluate the arguments left-to-right and push them on the stack.
- Execute the method.
There is this strong relationship between the caller and callee; the caller must push values on top of the stack in exactly the order the callee expects it, otherwise things go wrong. But there is nothing from preventing the caller to do all kinds of handling on the arguments, as long as on the moment of executing the method they are in the correct place.
So suppose we’re going to add ordering and defaults, what would that take? We know that in this case the arguments both in order and number may not match the parameters, so we need to treat those two parts as distinct steps, and have some kind of resolution logic in between.
- Allocate space on the stack for the local variables.
- Evaluate the arguments left-to-right and push them on the stack.
- Resolve the argument vs parameter difference
- Execute the method.
Let’s first implement this separation simplistically: first evaluate and push the arguments, then resolve the order and defaults by pushing onto the stack again (but in the right order), and finally execute the method.
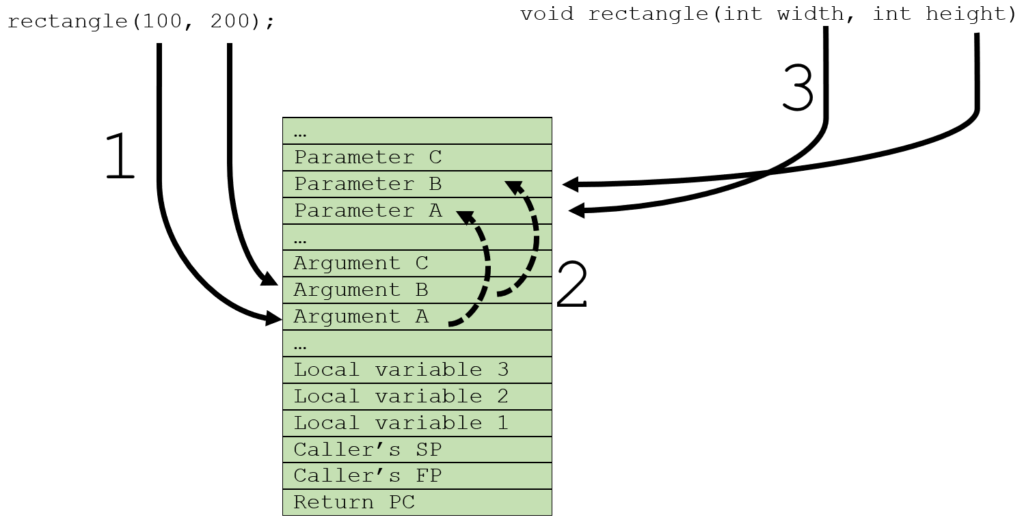
2) resolve the difference with the parameters,
3) access through parameters.
For the called method there is no difference; the parameters are still on top of the stack. And for the call there is also no difference also; the arguments are evaluated left-to-right. There is only a step in between that solves the discrepancy between the two. Like in the concrete example below:
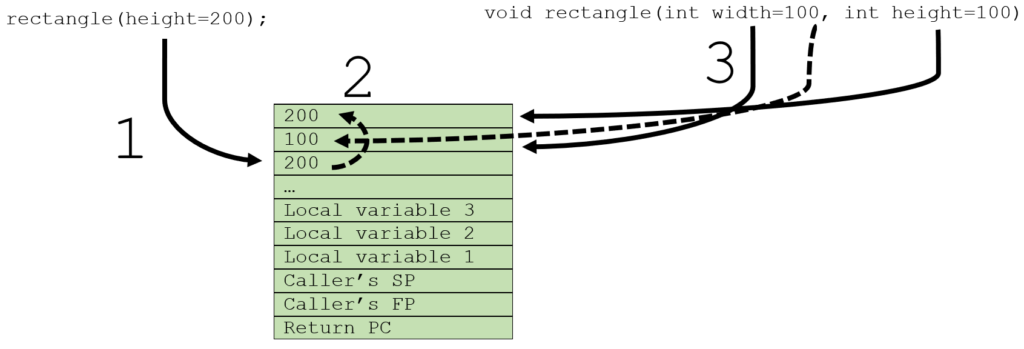
2) reorder it to second place, populating the first with the default,
3) access through parameters.
Naturally the compiler can be smart about this; if the call does not use names, or if the names are already in the correct order, there is no need for a resolution. Only if the compiler finds it needs to do some shuffling, the additional logic and stack space is needed.
Nevertheless this is not very efficient. Adding named parameters always means there is a price to pay; the reshuffling must be done, however having all this unused memory in stack frames is not necessary. By flipping the storage for the arguments and parameters on the stack, the argument storage can be released after the resolution. The steps of calling a method would become:
- Allocate space on the stack for the local variables.
- Allocate space on the stack for the parameters.
- Evaluate the arguments left-to-right and push them on the stack.
- Resolve the argument vs parameter difference by copying the arguments into the parameter space.
- Release the space for the arguments.
- Execute the method.
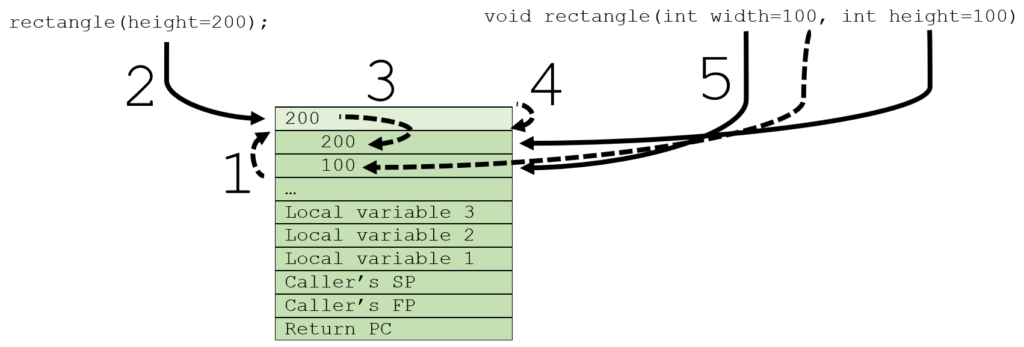
2) push the arguments,
3) resolve into the space for parameters,
4) release space for arguments,
5) access through parameters.
The end result of this process is an identical stack frame as with non-named parameters, so this approach is fully backward compatible. And no (long term) additional memory is needed, only additional code to resolve the difference.
Maybe someone can come up with an approach on how to do the left-to-right argument evaluation and parameter reshuffling in one pass, but I foresee issues. Any alternate approach would either change the argument resolution order, create overlap in parameters memory locations while reordering, or require many more copy steps. Changing the argument resolution order is not a good idea, because the behavior in my opinion would not be what a coder expects.
void rectangle(int height = 0, int width = 0) {
// ...
}
void use() {
int size = 1;
rectangle(width=++size, height=size); // rectangle(2,2) or rectangle(1,2)?
}
Some details:
- Either all arguments are named, or none. If some are named, the compiler will fail.
- If named arguments are used that do not match any of the parameters, the compiler will fail.
- If there are arguments with duplicate names, the compiler will fail.
- Parameters with defaults become optional, all other parameters must be present in the named arguments.
- Named parameters require that methods have the method names present in the class files. This is optional for javac. If the names are not present, the compiler will fail.
There are also some drawbacks / limitations:
- Changing the name of a parameter means that calling code that uses named parameters does not compile anymore. That could be in a lot of places. So changing parameter names becomes a non trivial activity. IDEs can help a bit here.
- It is not possible to detect if a parameter got its value because the default was used, or because the argument had the same value as the default.
I am very curious if I am missing something. But by writing this down I have figured out at least one complexity that I’ve missed so far. It is in the area of debugging and tracing; the direct relation between argument and parameter is lost, especially if we optimize the stack memory. So during debugging you see the values of the parameters, you see the all values (not arguments!) that are present on the caller’s side, but cleanly linking arguments with parameters is not trivial. I would be a bit better if we keep both arguments and parameters on the stack, but still the resolving logic is unclear.
Do you feel named parameters are worth it? Even if only for documentation and validation?
Not sure that fiddling with the stack is necessary. From a compiler perspective, it could simply rewrite any calls to named parameters under the hood. Turning the size example into something like this:
void use() {
int size = 1;
int __hidden_width=++size;
int __hidden_height=size;
rectangle(__hidden_height, __hidden_width);
}
.. and done. The rest of the compilation does it’s usual thing.
I’m sure there is more complexity involved, especially when overloads get into the mix. But having a version of it that works for the simple cases and simply forces the dev to fall back to the old style when it gets too messed up should already help.