
That title sounds like one from a boy’s book, a Tintin (Kuifje) or Spike and Suzy (Suske en Wiske) comic, but this blog is about Tesla, cloud computing, and hexagons.
In the middle of September 2020 Tesla suddenly blocked all network traffic originating from any of the major cloud providers, like Amazon, Google and Microsoft. A number of of third party Tesla apps were suddenly in big problems because of this, including my TeslaTasks. A lot of developers had to scram to work around that unexpected situation.

First let me say that it is fully in Tesla’s rights to do this, because all third party apps are using an unofficial API, only intended for Tesla’s own mobile app. This usage is at best condoned by Tesla, so it’s a fragile situation, but also mutually beneficial, I believe.
But that does not change the fact that all of a sudden TeslaTasks stopped working; the engine could no longer connect to Tesla to send commands to the cars. And the registration webapp could not inspect the Tesla account, and fetch the registered cars. My users were pretty quick in pointing out that we had a problem. But how to fix it?
TeslaTasks started as a finger exercise for Microsoft Azure. In my ‘Scheduling things on a Tesla‘ series of blog posts you can read how it evolved from a one-off workflow based implementation, to multi-account serverless functions. But the whole implementation was platform centric; Azure API first. And now that center was the problem. Basically I got slapped on the hands over the architectural choice I made; it was in no way prepared for change.
Naturally I had no time to thoroughly consider that in the stress phase; at that point I was foremost pleased with the fact that the database running on Azure was publicly accessible, so with a little hacking, and a crontab entry, I was able to at least move the engine to one of my own Linux servers.
Stress over.
But codewise it was messy; by letting the platform decide the code structure, I made the codebase inflexible. It didn’t take long to realize that this was because I had not used my all-time favorite architectural pattern: Domain Driven Design, or more specifically: hexagonal architecture.
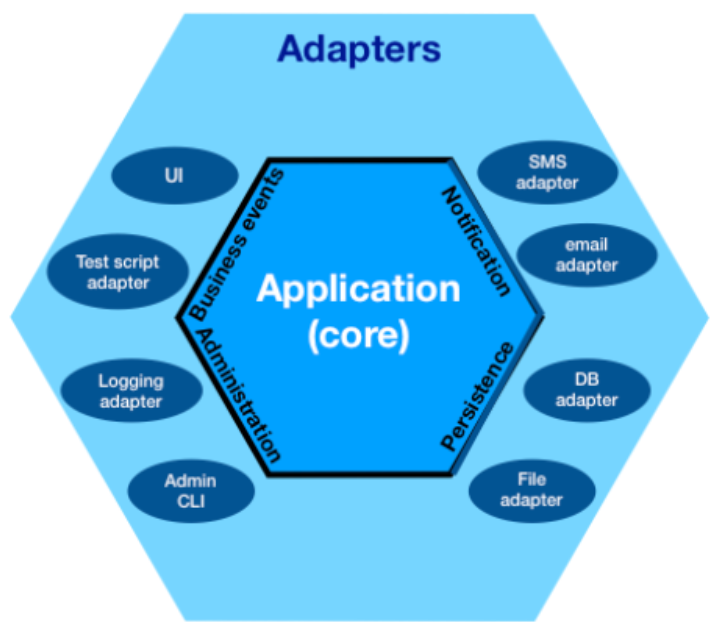
So during fall break, TeslaTasks was refactored; it now had a “model” instead of “azure” module. All the code was already there, in essence, it just wasn’t in the right place.
Now to the point of this tale: after refactoring I ran into the same issue I run into every time I implement such an architecture: how to make the implementations of the interfaces available in the model?
The interwebs all seem to nudge you towards dependency injection, but that means that you should not ever use the “new” keyword. That is a must if you want some kind of DI container to be the creator of the instances, so dependencies can automatically be injected. And because you don’t know where injection is need in the future, you need to assume the worst and do every instantiation via a factory.
I have tried that pattern a number of times, and every time it feels like an overkill. And usually I revert back to another pattern; static references. I know, I know, static is not done, but so far has worked out fine for me. Let me explain.
First of all the model of course only defines interfaces of what it expects from its outer layer. For example the car repository:
public interface CarRepository {
void save(Car e);
void delete(Car e);
List<Car> findAll();
Car findByVin(String teslaVin);
Car findByAccountVin(Account account, String teslaVin);
List<Car> findByAccount(Account account);
List<Car> findWithGoogleCalendar();
}
And this interface of course has at least one CarRepositoryImpl, somewhere. So how do I make an instance of that Impl available to, say, the domain service that implements the calendar scanning process?
Well, in my pattern the domain also defines a Repositories class, which holds static public variables. Nothing more, nothing less. Oh, yeah, because this class is used a lot, I shortened the class name to “R” (Android style).
public class R {
static public AccountRepository account = null;
static public CarRepository car = null;
static public CarProcessStateRepository carProcessState = null;
}
Using this from inside the model is simple, and IMHO it also quite readable:
final List<Car> cars = R.car.findWithGoogleCalendar();
CarProcessState carProcessState = R.carProcessState.findByCar(this);
And initializing it is also simple: the standalone module (containing classes to run things from the crontab) has Impl classes for all interfaces. And a class like this:
public class StandaloneBoundary {
static public void init() {
R.account = new AccountRepositoryImpl();
R.car = new CarRepositoryImpl();
R.carProcessState = new CarProcessStateRepositoryImpl();
}
}
All this results in the fact that the actual class being used to do the scanning of the Google calendar has two lines:
public class CheckForAndProcessEventsOnAllCars {
static public void main(String[] args) {
StandaloneBoundary.init();
new CheckForAndProcessEventsOnAllCarsService().run();
}
}
Simple and straight forward: initialize the boundary and call a domain service. So I’m really wondering why this pattern would be considered bad practice. I’ve used the same pattern for Factories (shortened to F) holding Supplier references. And the rest; classes that are neither factory nor repository, accessible through the Boundary class (shortened to B).
Testing is simple as well: I’ve created a number of stubs that implement the interfaces. I chose stubs because mocking can get complex quickly, and unlike stubs requires byte code generation. Also stubs can have helper methods, like the addDefault*-methods below. And then it is a matter of creating the stubs, assigning them to the R, F and B classes, and go.
public class AccountTest {
private final emailer = new EmailerStub()
private final TeslaStub teslaAPI = new TeslaStub();
private final CarRepositoryStub carR = new CarRepositoryStub();
private final AccountRepositoryStub accountR = new AccountRepositoryStub();
private final CarProcessStateRepositoryStub carProcessStateR = new CarProcessStateRepositoryStub();
@Before
public void before() {
B.config = new ConfigStub();
B.emailer = emailer;
F.tesla = () -> teslaAPI;
R.account = accountR;
R.car = carR;
R.carProcessState = carProcessStateR;
}
@Test
public void deleteAccountAndCarAndState() {
// GIVEN account with car and state
Account account = accountR.addDefaultAccount();
carR.addDefaultCar();
carProcessStateR.addDefaultCarProcessState();
// WHEN deleting the account
account.delete();
// THEN all three should have been deleted
Assert.assertEquals(0, accountR.accounts.size());
Assert.assertEquals(0, carR.cars.size());
Assert.assertEquals(0, carProcessStateR.carProcessStates.size());
// AND one email has been sent
Assert.assertEquals(1, emailer.messages.size());
Assert.assertTrue(emailer.messages.get(0).contains("car is disconnected"));
}
}
Again; simple, readable and straight forward. And this way of initializing works fine, because besides the Standalone module (which uses a relational database), there also is a Singleton module. In this module all the interfaces have been implemented to fetch the data from a single configuration file.
email {
host: "smtp.test.com"
port: "587"
password: "..."
user: "teslatasks"
}
tesla {
accessToken: "qts-ggerdfgdf3554"
refreshToken: "345465745gdfhfgh"
username: "me@test.com"
vin: "5YJSA7E28JF000000"
}
google {
url: "https://calendar.google.com/calendar/ical/erfsdfdfd34234%40group.calendar.google.com/private-ret54645tget34/basic.ics"
}
account {
emailaddress: "info@softworks.nl"
}
This is to provide my users an escape if the TeslaTasks service is ever discontinued, so they can run the TeslaTasks engine for a single car, triggered by a crontab. (BTW, that config is in TECL, not JSON.)
Why in the world would I want to replace this straight forward approach with the hassle of a DI framework? Please do enlighten me.

But in this case the output will be calls to the Tesla API. The lexer rules basically are regular expressions trying to match patterns in the stream of characters. The parser rules above them is what brings the structure to it all.